
Adobe Experience Manager (AEM) is massive. There’s a lot of confusion when most developers, content editors, managers, etc. come to this proprietary content management system. There are new terminology, processes and tools that one must understand. It can be overwhelming. Though it is impossible to write everything about AEM architecture in a single post, I wanted to write a post detailing some fundamentals for developers, but could still be read by anyone already working in AEM (using a language everyone can understand). So this is not a deep dive type of post. Understanding how AEM works will help you as a developer or author have a better insight into issues you may be having. My aim in the post is to give you the BIG picture. This is AEM architecture fundamentals.
AEM is a cloud based client-server system for building enterprise grade websites and applications. A copy of AEM running on a server is what you would normally hear of being referred to as an instance. The installation of AEM usually involve two instances running on separate machines on a production site. These is the author and the publish instances. Most of you know what the author instance is. This where you edit content. By editing content, i mean this is where you create, upload and management content on your website. Pretty much any website administration is done on the author instance (the name make sense since you are actually authoring content). Typically a content editor logs into AEM, edits or creates a page and either put their work in some kind of workflow for it to be approved, or perhaps they just publish the page when that content is ready (which goes live right away). What happens in the background, most of us don’t know. Here is where i want to shed a little light on because i feel knowing it gives you better insight into issues that might come up.
Author
So as a editor of content (author), you will be working on the author instance. Here is how the server is setup.

Here we have a single author instance (big picture view). Everyone that edits contents on your team does so on this server. In some advanced AEM setups, you can actually have multiple author instances. This requires a more advanced setup as the server instances have to all be in sync (reason its a more complicated setup)
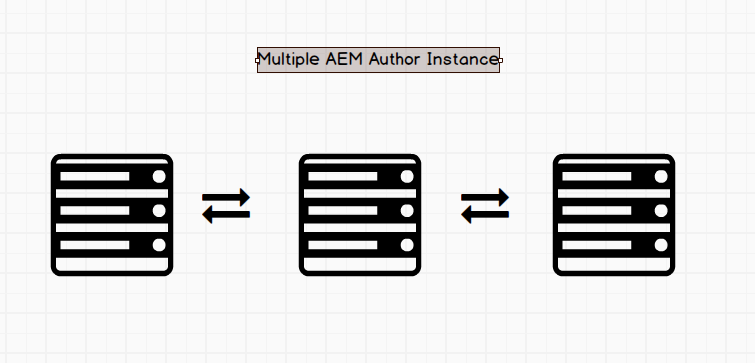
Typically such setups are hard to find. Most companies have just one instance of author but i wanted to mention type as well. Having multiple author instances means there needs to be replication agents put in place to sync all content. I will explain replication agents in a bit (but the name gives it away).
Publish
To push content that an enduser can see, an author would have to publish the page. When content is published, it is replicated to the publish instance. So replicated here is just a fancy word used for saying that content is moved from the author to the publish instance (sometimes referred to as publisher). Users that view your website (public facing) are actually getting content served from the publisher and not the author instance.
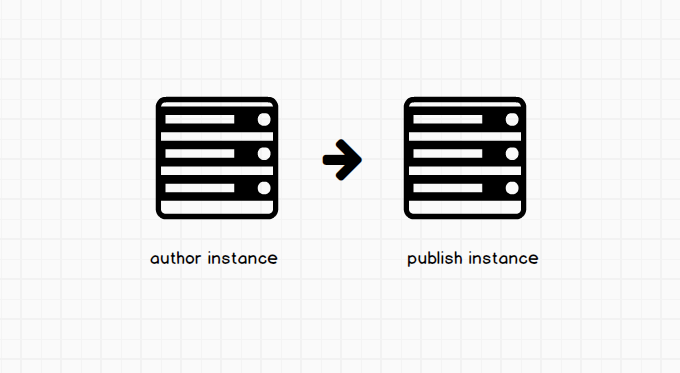
The diagram above is simply saying the author sends the published content or update to the publish server (ready to be served publicly). The page is now active and live. Activating and publishing a page are the same thing. You might be wondering where the publish instance is located. Since most of us are used to working on author. The publish instance is usually on lock down! and are located on a different network and ports than the author (there can be more than one publisher). This is done for security reasons we will be talking about soon. To enable websites to perform faster, AEM allows as to have what we call a dispatcher. It handles caching of web pages and load balancing. Having web pages cached means that we can get them quicker (they are static so can be served quicker). This speeds up performance on our site. Having a dispatcher means when end users come to your site, they first hit the dispatcher first, which serves them cached content. If a page is not on the dispatcher, the dispatcher reaches out to the publish instance for that content and then caches that page, just so it can serve it up quicker the next time anyone requests it. If the dispatcher always has to communicate to your publisher, this can lead to bad performance on your site, and sometimes can bring it down. I will explain why later, and give you tips on how to prevent this.
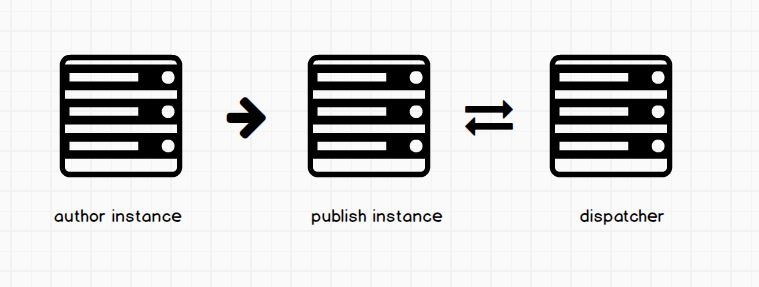
Above demonstrates how content is replicated from author, all the way to dispatcher. Notice that there is a one way communication between author and publisher (remember i said this was for security reasons), but bi-directional for publish and the dispatcher. This is so for a reason ( i already mentioned dispatcher reaching out to publish, but will explain more later). Lets look at the infrastructure for a typical AEM setup.
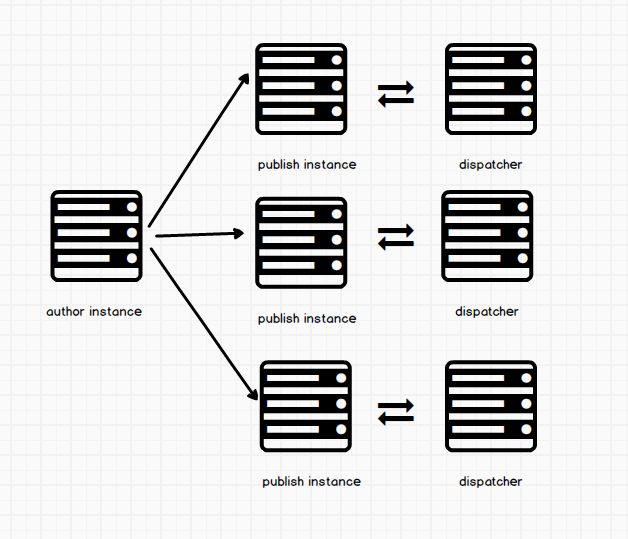
Earlier on i mentioned that most AEM setups have one author connected to a publish instance. Well in the real world, chances are you will find one author connected to many publish instances. This makes sense because you wouldn’t want the whole world connecting to one publish server. This can easily bring your site down (too many simultaneous connections). You can find companies that have 20 plus publish instances. Again it all depends on the kind of traffic you get. Some companies will add more publish instances on high season periods to accommodate incoming traffic. Some companies host AEM on Amazon and use a technology called auto scaling to automatically scale publish instances in peek traffic season. The same is true for dispatchers, since that is what is serving cached content.
When an author makes a change and actives them, they are sent to ALL publish instance asynchronously. Each and every publish node should get the update. Now for security reasons, there is one way communication between author and publish. When the author actives the page, it is replicated to the publish. But the reverse doesn’t happen. This is so that malicious code doesn’t come back to the author environment (which should be secured). Most production setups will disable any kind of tool on this instance (for eg CRXDE Lite). You wont be able to even add things to the DAM on this instance. It is important to understand this one way communication. One mistake new AEM users make might be to delete a page on the author side without deactivating the page. If you do this, the page will still be live. This is because the author never told the publisher to remove the page (via deactivation). The publisher has to be told by the author to do this. But in deactivating the page, the publisher is notified. Remember to always deactivate a page before deleting it. The same applies to developers adding CSS or Javascript to the DAM. Always deactivate before deleting, or your old files will persist on the publisher. There are ways to clearing the cache on the publisher when this happens (this might have you reach out to your admin).
Dispatcher
Earlier we mentioned what the dispatcher was. In the diagram above, it looks as if the dispatcher is its own server. This is a possibility as shown on the diagram. However the dispatcher could also be on the same instance as publish. You will find setups like these in some companies. Remember the dispatcher is only an apache (or IIS) module / plugin, so it can be installed anywhere (individually on a unique server, or together on a publish server). Typically an author or developer will not setup the dispatcher, however in the case of the developer knowing how it works will help put checks in place, so that you are not breaking it. Yes the way you write code can actually break the dispatcher.
The dispatcher is like a jack of all trade. It serves up static content, as well as act as a load balancer. You do not have to use your dispatcher as a load balancer however. A load balancer is a device that distributes network or application traffic across a number of servers. Load balancers are used to increase capacity and reliability of applications. If you choose not to have the dispatcher doing the load balancing, then your infrastructure begins to look like this.
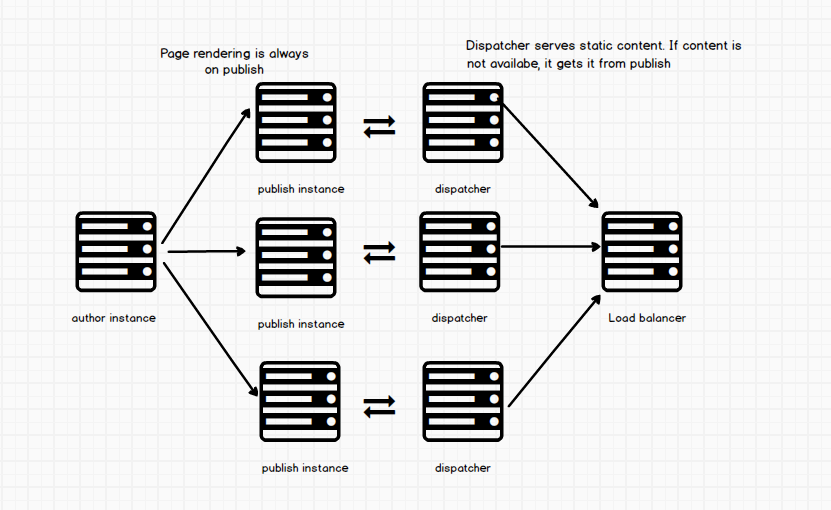
In this case, users that come to your site first hit the load balancer and that directs them to which dispatcher to connect to. It distributes users to the right server and prevents overload on our servers. Here is another visual adding (adding the content editor and someone accessing the site)
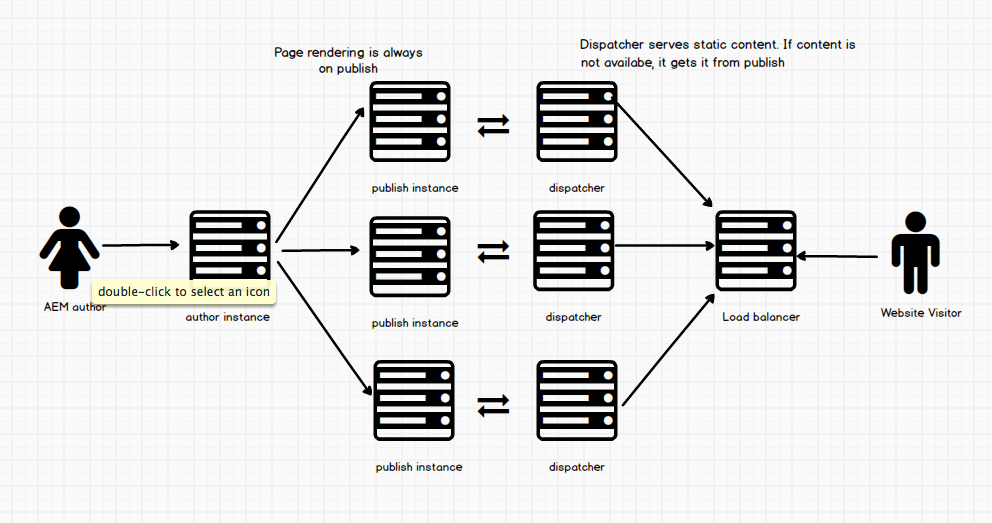
Let us look at the dispatcher workflow.
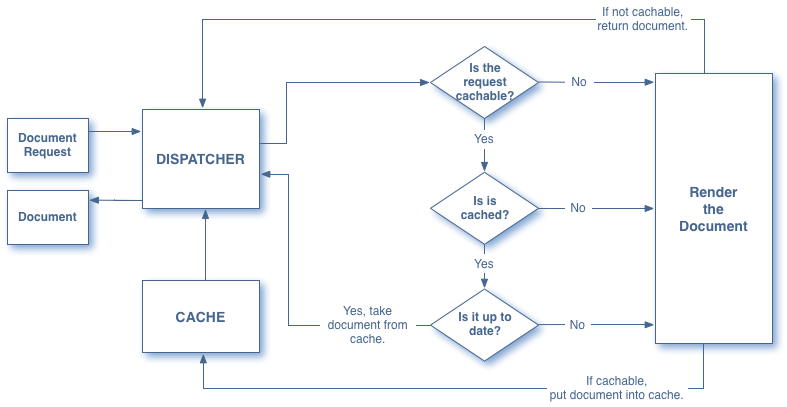
Lets look at how the dispatcher does caching of pages. The diagram above helps us understand what is going on. When an end user requests a page on your website ( referred in the diagram as document request), it hits the dispatcher first. The dispatcher then runs through a series of checks ( see diamonds in figure ). It checks to see if the page is cachable and it is up to date. If the answer is yes, the dispatcher takes the document and gives it back to the user. If the document is not cachable (like a page that requires authentication), the dispatcher gets the page from the publisher and sends the page to the end user. It is never cached in this case because it falls under the category of uncachable pages. There are other cases where a page would not be cached. Perhaps its a new page, and since this is the first time, the dispatcher doesn’t know about it. It has to be requested from the publisher. After the first request the page is however cached, so it can be served up more easily. The dispatcher is your friend, it helps us serve content faster! Now here is a big time. When developing applications, you have to try as much as possible to make sure the content can be cached. What you want to do is make sure users are hitting the dispatcher more often than the publisher.
The dispatcher can be configured to define which documents are cacheable, if not it checks against a list of cacheable documents. If the document is not in the list, the dispatcher requests it from the publisher. So let see some cases where the dispatcher will do this. Remember that these are cases you want to try to avoid when coding your sites. You can find these here, but i will save you the trouble of explaining it.
- If the HTTP method is not GET.
- If the request URI contains a question mark “?”. This usually indicates a dynamic page, such as a search result, which does not need to be cached.
- The file extension is missing. The web server needs the extension to determine the document type (the MIME-type).
- The authentication header is set (this can be configured)
A lot of ajax calls use the GET method to get information it needs. Using POST over GET means the content is being saved somewhere and shouldn’t be cached. So use post wisely (only when information needs to be posted and not when getting information). In a nutshell use GET over POST. The next on the list is URL parameters. I have seen entire AEM sites come down because of this one. If you are going to be passing lots of query string around AEM is going to cache them. You can find your dispatcher hard driver getting full from this (potentially bringing your site down). There are solutions are these problem, like using sling (a framework use to resolve url requests) or perhaps some configuration on the apache server or even the dispatcher. If you need pages with url params to be cached, please reach out to your admin. If a file extension is missing, the rendered page wont be cached. You can override these settings on the dispatcher however. Finally AEM will not cache pages that are authenticated. Again, this can be overridden in the dispatcher.
A good friend of mine recently ran into a problem in AEM i would like to share. Above you see the point i make about the dispatcher setting content type based on file extension. He had a JSON file name as .html working fine from the publisher (it had the correct content-type: application/json!). However once it made it to the dispatcher it stopped working because the dispatcher forced the content type to text/html. If you understand all these different environments in AEM you are better able to find out issues you might have in your day to day activities.
Replication Agents
We learned earlier that when content is published it moves from the author to publish. This is possible because of replication agents. This is more of an advanced topic, so we will touch on it lightly (chances are you will never have to configure these). Replication agents allow author to talk to publish (think of them as messengers or connectors). The only way your authored content is able to get to the publisher is because your admin has set this up. These agents can be configured on the author or publish instances. You will find all sort of options when trying to configure replications agents. You will find default agents that replicate to publish from author, agents that send flush requests to the dispatcher (imagine a messenger sending a request to clear cache), you can even find agents that replicate from the public facing site, back to the publisher (this is called reverse replication). Now remember i said the author and publish have a one way communication flow? This is done for security reasons, and most agents on the publish server are disabled (intentionally).
Normally we want our authors to push new content onto our websites, but we don’t want content coming back our author from the publisher. It could be malicious code that could break our author environments. However, in websites where end users generate content (ratings, comments, etc.), its possible to have an agents that replicates content back to the publisher they were created on. Generated content is saved in the content repository on the publish server and has to go through some kind of approval before seen on the website. Once content is approved it is replicated to other publisher servers in the environment.
Environments
Having a good environment in place is crucial for success AEM projects. I cannot speak enough about how important this is. Environments can be a complicated topic though, so we will only be talking high level. Even that, it can get a little confusing. This section will be best for developers to read, however i will use very simple words so anyone can understand. Lets first start with a diagram.
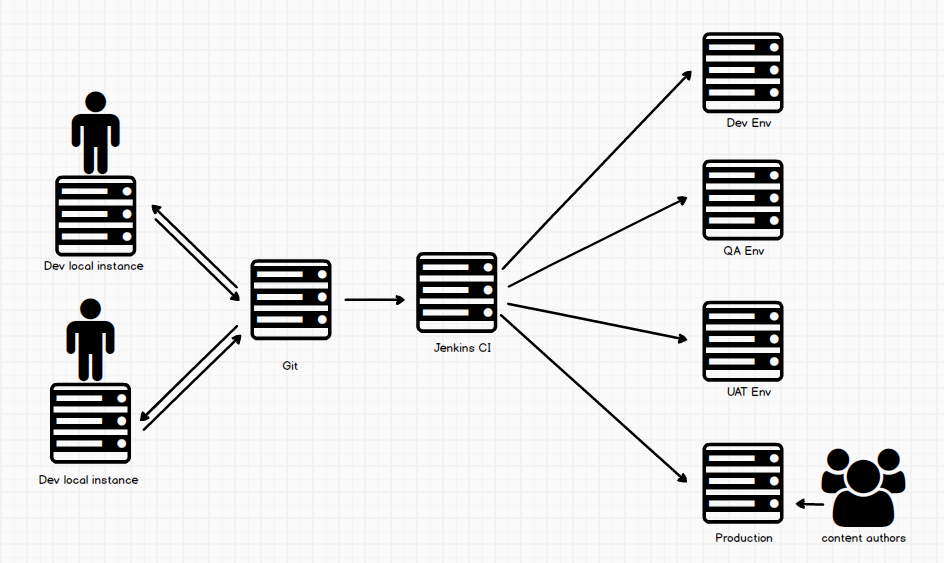
Most of the discussions we have had, put an emphasis on content authors. Lets add other players in the environment. As you can see on the diagram, we have content authors working directly on the production server. This is so because these guys are not making code changes. All they are doing in editing copy and images. Since this changes so rapidly, its the best environment for this. If we you writing code directly on your production servers as an author, know that this is very bad practice. Injecting code onto a site without it going through the right channels can bring your site down. And it is hard to find out who introduced the breaking code changes. All code changes need to go through some kind of deployment or build system (such a jenkins). The best practice is to have content editors do basic operations, like edit or add new content, or image changes.
The diagram above is not how all AEM environments are setup. It introduces some third party tools that are NOT specific to AEM (remember no single system solves everything). This setup is what i am most familiar with, so that is the information i share. However i know many AEM developers that have a similar setup. If you are using a different setup, kindly share with me! The development process starts with first setting up a local instance of AEM on your computer. Some shops might run an AEM jar off their desktops, others might setup vagrant to do that. With AEM setup you have available to you all the default code base that comes with the CMS. Since chances are you are going to build on top of that code base, AEM gives you the power to extend its built-in components and even create your own from scratch. This can be frontend code written in HTML, CSS and JS, or backend code like Java. All this code lives on your local developer instance.
Now since we live in a world where sharing is everything, chances are you working with a bunch of developers who are also working in this codebase. When that happens, you almost cannot run away from using a third party version control system like GIT. Git allows a team of people to work together, all using the same files. So we can have many developers collaborating on a project using this technology. When a feature is fully developed, a developer will normally commit their code to the repository so its available to all team members. Sometimes when code is ready, it actually goes through a code-review process where other members of the team review the code. If there are any issues, it is kicked back to the developer for him/her to continue working on it. If the code is good, it is pushed to a Jenkins server for that code to be merged into another AEM instance. You can even tell Jenkins to run extras tests or build on the code deployed to make sure there aren’t any errors or the code meets a best practices guide. You can run builds for Java using Maven or even frontend builds (with gulp, grunt or anything you want).
With the code now on Jenkins, there are jobs that run to deploy code to other environments. For e.g, there can be a developer environment where all code ready gets deployed to for testing. This is different from the local environment. It could also be deployed onto a QA server for it to be tested. Other environment where it can be pushed to are a UAT or Production environment. Its advisable that you run your code on different environments before it gets to production. This is way you know its properly tested.
Components
Components are everywhere in software development. They emphasize a separation of concern with respect to functionality in a system. In AEM, components are modular units that are created with a specific functionality, to render content on a web page. Lets say we want to render a list of items, well we could have a list component. Need functionality for breadcrumbs? Just add the breadcrumbs component. The list goes on and on. We can think of components as a collection of scripts working together. Scripts here may be a Java servlet, JSP’s (Java Server Pages) or HTML Templating Language (HTL). In order to create a component in AEM you could use any of these languages. Lets just say you wanted to create a page template component. This is a component you may want to use to create a specific template on a website. You could use any of the languages mentioned to build it. However in the world of AEM, Adobe recommends that you use HTL. You will find others calling it Sightly as well, so be familiar with both names. HTL is a markup language, but before it came into AEM, we used to have to write components in JSP’s . This wasn’t so friendly – in my own humble opinion. Mixing presentation and logic in a document is really not best practices. With HTL you are able to separate these concerns better. If you are a frontend developer, you would use HTL to build your components (as of AEM 6.0 or higher). However if you are a backend developer, you would use Java. It also depends on the functionality you are building. But you would normally find components that are a fusion of HTL and Java or Javascript. Since HTL is a templating language, it allows you to write the visual appearance of your component(in HTML/CSS/Javascript). However if your component needs data, you might have to import a java or javascript model into your template so that data is accessible. The backend logic is not mixed in, like you would see in PHP or JSP type of applications.
AEM ships with a large number of components! You can use these to add specific functionality to your websites. Out of the box you get access to components like page, list, responsivegrid, title, image,video, login, logo, slideshow, and many many more. Check out (libs/wcm/foundation/components and libs/foundation/components directories in AEM) for the entire list. Components found in /wcm/, are Touch UI based, where are the others are Classic. Lets take a little fork in the road. Historically AEM components were built using a javascript framework call ExtJS. Adobe is however moving away from it, and component development now use a framework called Granite UI. So when you hear “Touch”, it means it was built using Granite framework. Components built in touch have some advantages. One example is it allows authors to edit and build pages in AEM, on a tablet (for example). Touch is mobile optimized, unlike classic. Since mobile is everything these days, Adobe has shifted to a more flexible UI framework when building pages. Know that you will still find Classic based components in AEM. This is because Adobe has not finished converting all their components to use Touch. Lets get back on course!
Chances are there is functionality missing with what you get from out of box components. Well, no problem there. You can extend component functionality. In AEM you can build your own components while inheriting functionality from base components. This is very helpful, because Adobe has written most of the code for you already. You can focus on adding whats missing, instead of re-writing a ton of stuff. Most AEM works extend built-in functionality, so do not be surprised when you see it. Components that ship with AEM are normally called foundation components.
The way authors use components when building pages, is by drag and drop functionality. Just drag the component you need into the content area of the webpage. In AEM areas that you can drag components into are also components. We call it the paragraph system (parsys) component. With a parsys, you can control the areas where authors can add content. You dont worry about writing more code on the page for the author, you just leave that to the them add what they want. There are column and layout components that help authors structure how content looks on a page. Adobe recommends that you use the parsys as much a possible as opposed to using a lot of different templates which developers end up maintain.
As a developer, when building components in AEM, you have to think about the authors who are going to use it. For example, you just built a video component that allows the author to add any youtube video onto your site. The author picks up your component and drops it into the content area (parsys) as they build their page. How do they configure your component? In AEM, when building components, you have a build a dialog user interface that authors will use to configure your component. In the example of the youtube component, the author needs to be able to enter the size of the video, plus the URL as well. An author is able to hit a configuration button on the component, which pulls up this dialog. In there, they are able to provide the data that the component needs in order to function correctly. The author changes are saved in AEM (content repository), and the component is ready for use. When building dialogs you use Granite APIs. You can also write them for classic UI’s if that is part of your requirements. This means the author will be able to use configure your component in Touch or Classic. It is important to gather the right requirements during the component development phase, and understand how authors will use it.
In AEM, there is a concept of client libraries (or clientlibs). When building components you are able to write component level CSS and Javascript, as well as import third party libraries that your component will need. This is important if you want to create great user experiences. Now while this sounds exciting it is not easy, as AEM has to find a way to load the right libraries that are associated with your component. Since the author can choose any template or component during the authoring phase, AEM needs a way to load any libraries that are associated with the component/template that the author is working on. Clientlibs are folders that contain client side assets (html, css, javascript, fonts, images, etc). And these folder contents can be loaded individually at anytime. They can also be purged (in cases where you have updated the clientlib, but new changes are not showing up). The cool thing able client libraries are that they can be given a namespace. Anytime you need functionality in another component, you can just reference that clientlib and voila! all that functionality is available to your component.
Conclusion
So here you go! You now have the BIG picture when it comes to working in AEM. But guess what? We have not even scratched the surface. Its a whole new world diving deeper into the individual core technologies behind AEM. Things like OSGI Bundles and framework, workflows, components, client libraries, content repository, etc. The whole point of writing this post was to give you an overall insight into working with this tool. Thanks for reading and i look forward to hearing how you are using AEM at your companies. Feel free to reach out on twitter as well ( @scriptonian ) if you have any questions.
Nice summary. Thanks for sharing, Coffee 🙂
Looking forward to read about targeting & campaigns!
Hello Sneha! Appreciate your feedback. I will surely consider your request and update this post in the future. Thank you!
Cofveve!!!!
i am new to AEM and a product manager. The content and the basics that you have given and explained is really great. Without having much technical knowledge i was able to understand and get a gist of what AEM is, how the environment works, its ecosystem etc. So thank you very much for that.
Sandeep! thanks for your comment. I really appreciate it (sorry for the delay in replying)
Hi – Very well explained article – makes a nice and easy reading. I have couple of questions:
1. How is the content served from the Publisher to the Dispatcher in cases where it is not cached at the Dispatcher level? Is it via http protocol? If so, does Publisher compresses the content (i.e. content-encoding) before delivering it to the Dispatcher?
2. The reason I ask above question is that we are getting 4 TPS for pages served from Publisher compared to 50+ TPS from Dispatchers. What could be the limiting factor? Is it the way Publisher trying to locate the content in the first place or how it delivers to the Dispatcher?
Any pointers on these questions will be really appreciated
Very helpful, thanks for the post
Nice blog to have a great basics of AEM. Good work.
Great and easy to understand summary. Thanks!
You are very welcome. Thanks for reading!
Seriously well explained, lots of appreciations to you.
Welcome Sai 🙂 thank you so much for leaving me feedback. its encourages me to keep writing.
Awesome summary. This would give a nice birds eye view to anyone wants to learn about high level overview of AEM.
Thank you Aboo! Appreciate you leaving a comment 🙂
Awesome Explanation and Good article
Really appreciate the comment 🙂
Thanks for great summary. This article helps people who doesnt know abcd of AEM.
Thank you! Appreciate the feedback 🙂
Excellent post. Nicely explained. Appreciated. Thanks
Thank you Venkat! You are very welcome. I hope to write more in the future.
Really great explanation Kofi, Thanks for putting it together!!
Please write more on this module 🙂
You are welcome Sai!! Appreciate the feedback!
Simple and beautiful explanation. Appreciate the hard work.
thank you so very much Sambit !
Very well written. To the point. Thanks for sharing! Looking forward to learn more from you.
Big smile on my face Viresh! I really hope to find time to write another post.
Very well explained, I’m glad that I found this post. thanks a ton Kofi 🙂
Thank you Dhivya! Thanks for the positive comment 🙂
You nailed it down. i was looking for something exactly like this not too detailed and not ultra high level. Thanks for sharing.
awesome!! thank you @rashpal 🙂 appreciate the comment!