
A tree data structure is very similar to a linked list. Where linked lists are linear (meaning we have each node in the collection pointing to a next node in a fixed sequence), a tree data structure is non-linear. This means we can have each node potentially pointing to one or more nodes. Think of a trees as a way to order things hierarchically. Example are, graphical representations of data (like an organizational charts), files in a file system or even sorted collections of data. When working with trees, order of the elements is not important (if it is, you can store your collection in a linked list, stack, queue, etc). Lets take a look at an example of an organizational chart ( a type of tree structure showing hierarchical data ).
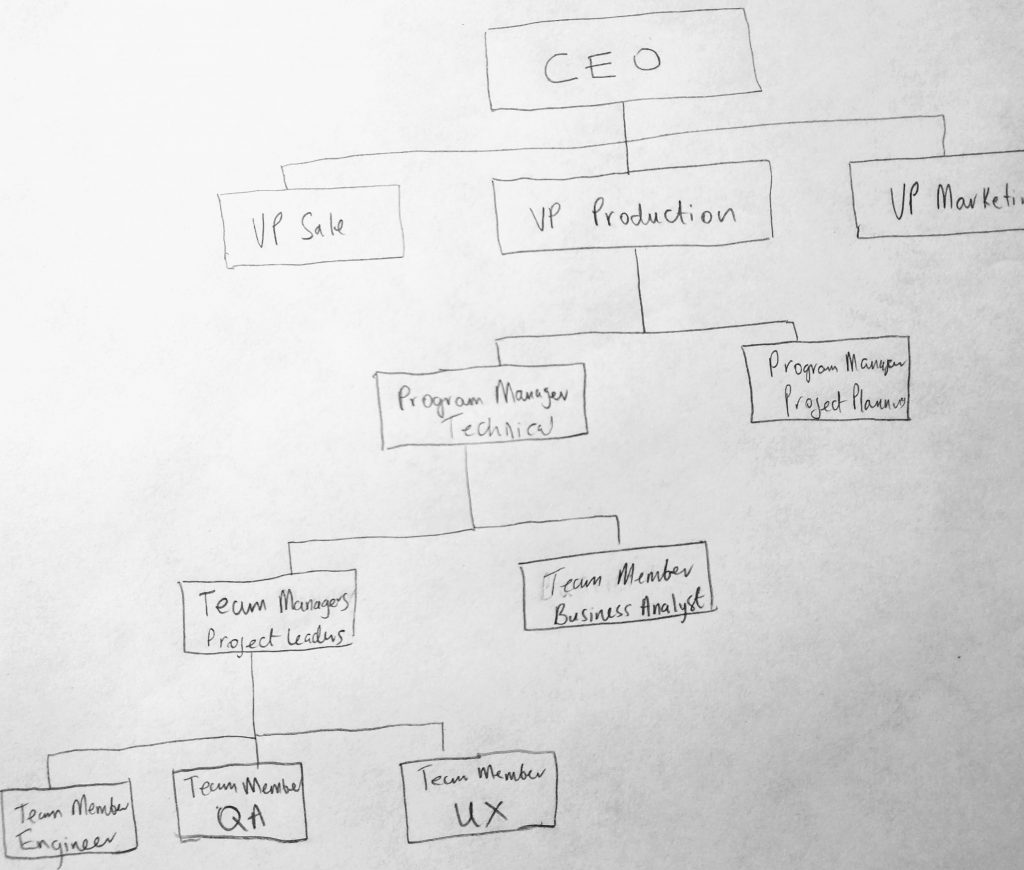
Here we see an example of an organization chart (which we are using to represent our tree). It represents a logical way of thinking about how things are structured in an organization. We are not interested, lets just say, in where one node is located in memory, but how it represents data logically. We can see who reports to who in this chart (hierarchy). For example the Team Managers report to the Program Manager who reports to the VP of Production, who then reports to the CEO of the company. The diagram help us make sense of complexity in the real world. Lets look closer at the various parts of this data structure.
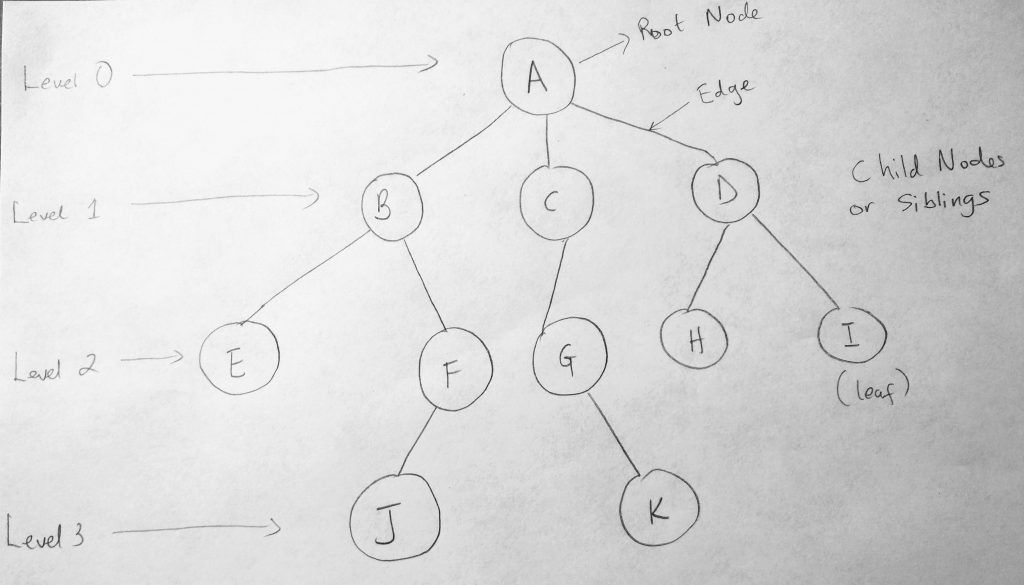
Trees can be broken down into levels. Level 0 represents the root node. There can only be one root node in a tree data structure. Its the node with no parent (Node A is not derived from any other node). Going down the levels we have 1, 2 and 3 which represent child nodes. B, C and D are child nodes of A, but you can also think of them as parent nodes. For example B is a child of A, but E is a child of B. Because E does not have any children, we call E a leaf node. Nodes that exist on the same level are called Siblings. Just like your siblings are derived from the same parents. The link between nodes are called Edge. You can also have subtrees, which are cluster on linked nodes. For e.g B, E, F & J are a subtree where B is the parent of the tree. Pretty simple to understand. Now here is where things get interesting. Notice that we have 3 child nodes underneath Node A (the root node). While this is still a tree, there is another way of representing tree data structures where you have no more than two nodes children for every node. This is what we call a Binary Tree. From Binary Tress, we can derive Binary Search Trees (BST): A way of searching through tree data structures based on certain rules. We will be looking at that soon, but before that, lets look at Binary tree diagrams.
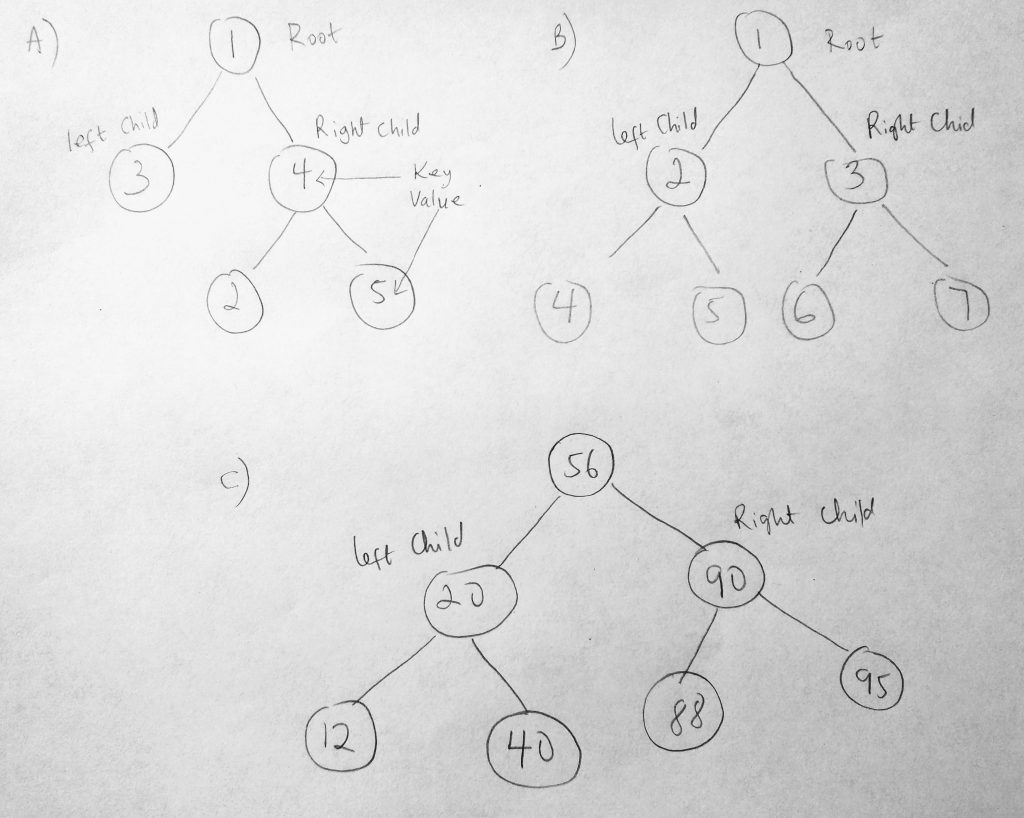
Lets try to make sense of this tree. I have 3 binary trees in the diagram. As you can see each node can have no more than 2 child nodes attached to it. It can have 0, 1, or 2 nodes only. Looking at figure A, the root node is 1. To the left of 1 is 3, and to the right is 4. We call 3 the left child and 4 the right child. Lets consider these numbers as key values for the nodes. Since each node is essentially an object in the collection, we will use these numbers to represent each nodes key. Now the rule when working with BST’s is that, when we add new nodes to the collection (starting at the root node), if a node is greater than the root, it goes to the right side of the tree. If its less, it goes to the left side of the tree. So looking at figure C, 56 is the root node. When we added 20 and 90, 20 went to the left, since its less than 56, and 90 went to the right. When we added 88, it also went to the right side as well. However since we already have 90 as a child, it goes to the left of 90 as its child. 95 was however placed to the right of 90, since its greater. This is how we add things to a tree data structure. So figure A and B only shows you the parts of a binary tree BUT it does not have rules applied to it. Now what happens when you add a value that is equal to the root node? The rule for that is to go in the direction of greater than (to the right). If i add 56, it would go to the right. When it gets to 90 it will branch left, and when it gets to 88 it will branch left again.
Now you might be wondering why use this way of arrangement? Well it turns out that by doing things this way, you can write programs that make inserting, searching and deleting data very efficiently! You might also be thinking: “thats what a Hash Table do!”. And you are right to think so. So why would we just use a hash table? Why do we have to implement a binary tree? Because it is a data structure that naturally remains sorted as you add child nodes. This is not so for Hash Tables. So if this is part of your application requirements, then this data structure might be best for you to use. Because BST’s stay sorted, we can get all the items in the tree in order, which can help to enumerate things in sequence (hash tables don’t give us that support). This uniqueness gives the tree its power to search. When its time to find a node, say 95. The tree naturally knows which direction to go in. This help eliminate searching other larger portions of the collection. For example in figure C, looking for node 40, the tree would start searching in the left side of the tree, eliminating have to look at node 90 subtree.
It not unusual to have a binary tree that is skewed as you add data (to the right or left). This produces a left skew or a right skew tree. Lets see how this is represented.
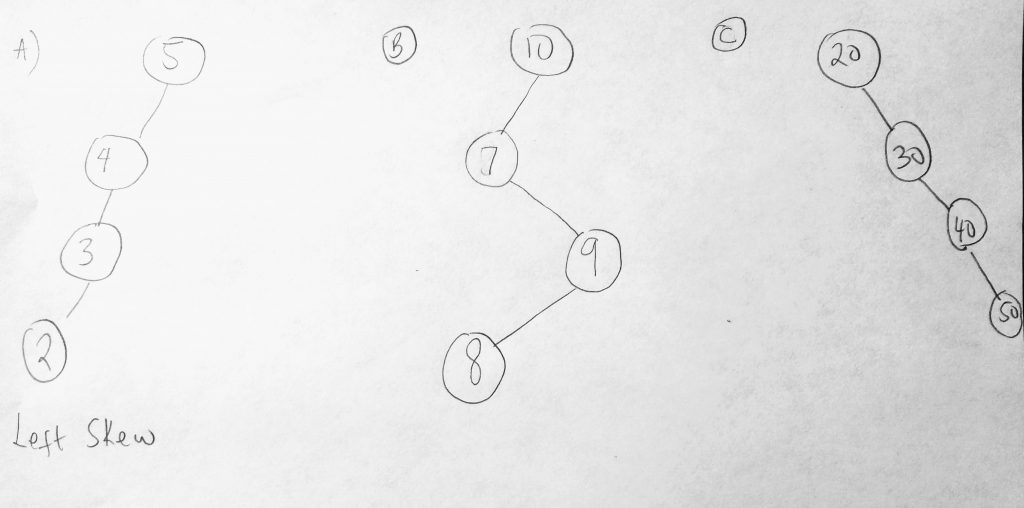
If you look at figure A, B or C it makes sense why there is a such a skew. In A, we have 5 as a root node and it only makes sense to insert nodes to the left based on the nodes values. The collection is skewed to the left. In C, they are skewed to the right. In B, we call this type a skew tree. We cant always guarantee that the structure will always be symmetrical. Some binary search tree implementations have algorithms which can help the tree to self balance. This helps balance the difference levels. Some algorithms used to balance binary trees are: Red-Black trees, AVL trees, Scapegoat trees, splays trees etc. Note these are not data structures, they are algorithms. We haven’t gotten to the algorithms section of this series yet. Before we start implementing our BST lets take a look at a diagram which will help us write our class.
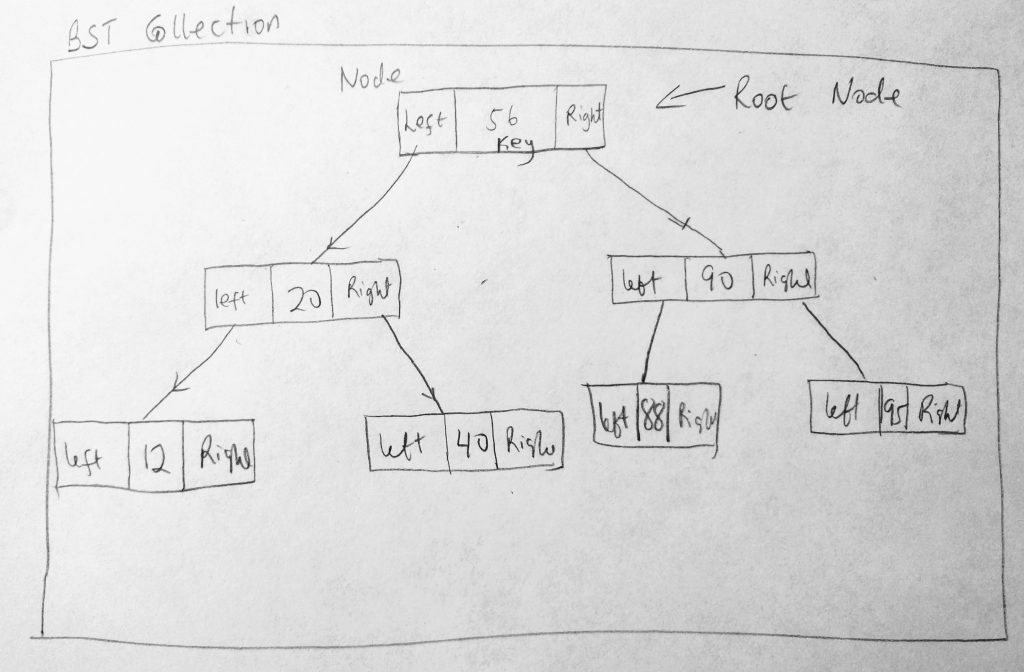
The above diagram will give us an idea how we are going to code our BST class.Each node in a BST has a key value, as well as a pointer to the right and left child. It can have other properties (like a counter, etc).The class also has a root node. Lets use these ideas to construct a class.
Binary Search Tree Implementation
Lets write the basic shell of our BST.
See the Pen BST Shell by kofi (@scriptonian) on CodePen.
We are all familiar with this pattern by now (if you have been following up with my other data structure posts). Based on the diagram we create a class to represent nodes that we will add to the BST (TreeNode). We know that a node has right and left pointers, pointing to another node. We also know that each tree node has a key value. So we use this information and create the necessary properties on our class. We also created a toString method to help us identify the node. Next we create our main class, the BinarySearchTree class that will house tree nodes. It only has one property (the root node).
What we will be adding next are methods on our BST class. Some of the operations we will be looking at are insert, find, remove, maximum, minimum, and how to traverse binary search trees ( inorder, preorder and postorder traversal), many more. Lets add these to our shell structure.
See the Pen BST Shell Enhanced by kofi (@scriptonian) on CodePen.
Adding to the BST
With our shell in place, lets talk about our first operation. We are going to see how we add a node to our BST. We will do this using our insert method. Adding items to tree data structure is done by using recursive algorithms. The process in which a function call itself directly or indirectly is called recursion, and the corresponding function is called as recursive function. BST’s use algorithms such as these when adding nodes to the collection.This makes it efficient as the runtime complexities of recursive algorithms are O(log n). Lets take a look at this process.
When we try adding a node to a tree collection, the following scenarios are possible. The first is that the collection is empty. If its empty then the node we are adding becomes the root node. If the collection is not empty, then there is already a known root node. We must then use some rules to add this new node to our collection. If the node being added is smaller than the current root, it is sent along the left side of the tree (to the the left child of the root). And if an even smaller node is added, it is added recursively to the left. The means we keep calling a function, which continually places the node in the left side.
Lets try to get a mental view of this before we continue. We have an empty collection, so we decide to add some nodes to it. We start off by adding 10. Since the collection is empty, 10 becomes the root node. Next we add 5. Since there already exists a root node, and 5 and smaller than 10 it is added to the left side of the tree (the left child of the root). Next we decide to add 1. Again, there is already a root, and 1 is less than 10 so we move along the left of the tree. First we reach 5. We notice that 5 is greater than 1 so we push 1 along the left side of the tree again to be the left child of the 5 node. Get where i am going with this? We have recursively added it to the left. And we will be doing this a to add nodes to our collection. Lets dig a little deeper into this recursive process. We know that when we add a new node to a collection, it either goes in as a right child or a left child if a root node already exist. If not recursion occurs to until add occurs. When this happens a function responsible for node insertion is called(repeatedly). What this function does is quite “simple”. It starts from the root node. If a the new node is less than the root, it check to see if the root node already has a left property. If the root node does not have a left property it means that spot is available and the new node can be inserted there. However if the root nodes left is not available, then we need to move further left. We call the insert function. We keep calling it till we find an available left property. The same thing happens moving to the right side of the tree. Hope this is clearer now. Lets move on.
Another scenario that could happen is that we add a node that is larger than the root node. When this happen the node will be added as a right child to the root node. And adding larger values will be added recursively to the right as well. What if we add a value that is already in the tree? When this happens, we are going to treat it as a larger value. Remember we only have two directions we can move in. Either we send it to the right or left. So equal values are sent on the larger than path (to the right side recursively). I think i have over explained here. Ready to write some code? Lets do it!
insert()
The first method we will implement is how to add new nodes to a BST data structure. Lets take a look at the insert method.
See the Pen BST – Insert by kofi (@scriptonian) on CodePen.
When insert is called, we first create a new TreeNode with the key value passed in. If the BST root is null, then the collection is empty and we have to assign the passed in key value as the root node. If it is not null, then we call our recursive function to do the insert operation. This function takes a node where we want to do the insertion. We called this the positionNode in our code (call it whatever you want). When this function is called, it first checks to see if it should insert the to right or left side of the tree. When that is determined it checks if the position nodes left or right property is null. If its null then we have an opportunity to assign to the left/right property, if not it means the left property is already taken. We call the insertTo function again. However this time we want to call insertTo with a different position nodes (since we keep traveling along the node path till we find where to insert). Finally we increment the count (helps us know how many nodes there are in our collection). Take a closer look at the code and let us test our insert function. Lets create a BST with these numbers: 60, 30, 85, 95, 80, 35, 20 (which look like this after we apply our rules).
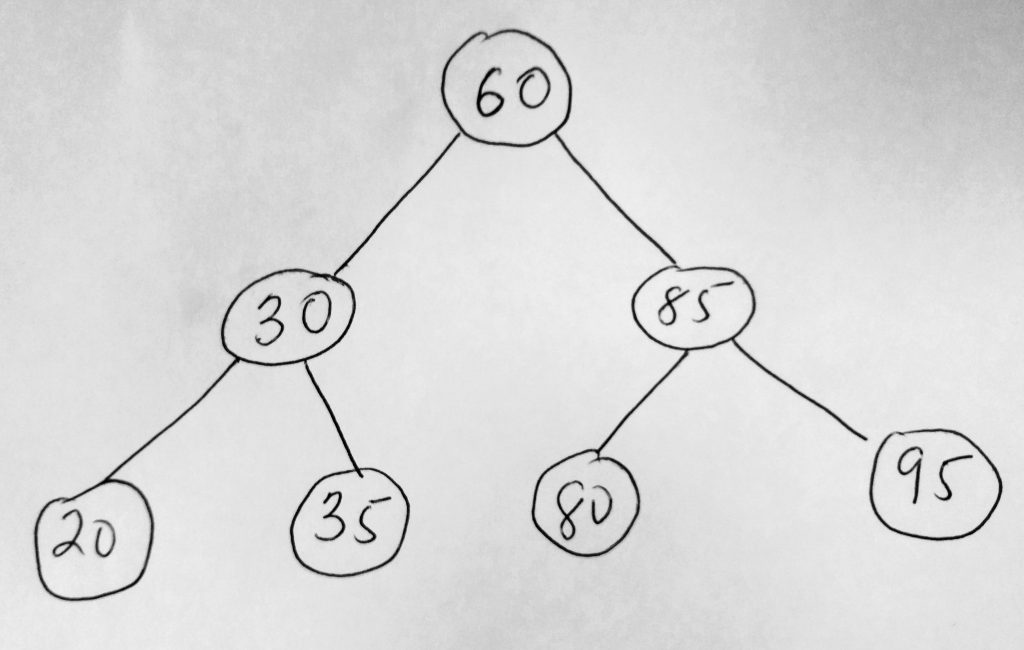
Now lets see if we can see this same relationship in our console if we insert this numbers into our own BST. First our test code:
See the Pen Binary Search Tree – Insert Test by kofi (@scriptonian) on CodePen.
Here is our console log.
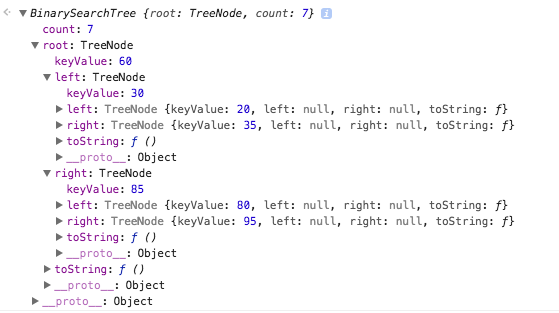
We see we have a total count of 7, which represents the number of nodes we have in our collection. The root node has a key value of 60, which was the first item we added to our collection. Then we added 30 and 85. Since 30 if less than the root node 60, it goes to the left side and 85 goes to the right. In the console you can also see the child properties of 30 and 85. For example in our diagram 95 is the right child of 85 (exactly what our console reports). This means our insert is working. Go ahead and add more nodes to verify that it works for levels more than 2. Lets move on and learn how to traverse our binary tree.
Traversing a Binary Search Tree
Traversing is something we do on a daily basis as software engineers. When working with collections of data, there is always a need to iterate through them. Traversing a BST means running through all nodes in the collection and performing an action on them (for example printing all key values). It turns out there are 3 traversal functions when working with BST’s (thats moving through the tree in a particular order). The first visits all nodes in the collection, in order as ascending key values. We call this the inorder traversal. This traverse makes a lot of sense and i don’t really need to explain why we might want it. The other two preorder and postorder are quite weird in the way they operate. Preorder traversals start at the root node, then traverses all the nodes to the left child of the root node (left subtree or branch – A subtree/branch are nodes underneath the root). Then finally, it traverses all nodes to the right child of the root(right subtree). Postorder starts by traversing children of the left subtree, then through the right subtree. After that it ends on the root node last. Here is a summary of the 3.
InOrder – Start from left subtree in order (smallest) all the way to the root (middle), then traverse the right subtree to highest value.
PreOrder – Start from the root node. Then traverse the left subtree and then traverse the right.
PostOrder – Traverse the left subtree, then traverse the right, then finally end on the root.
Lets take a look at a diagram that will help us understand even more.
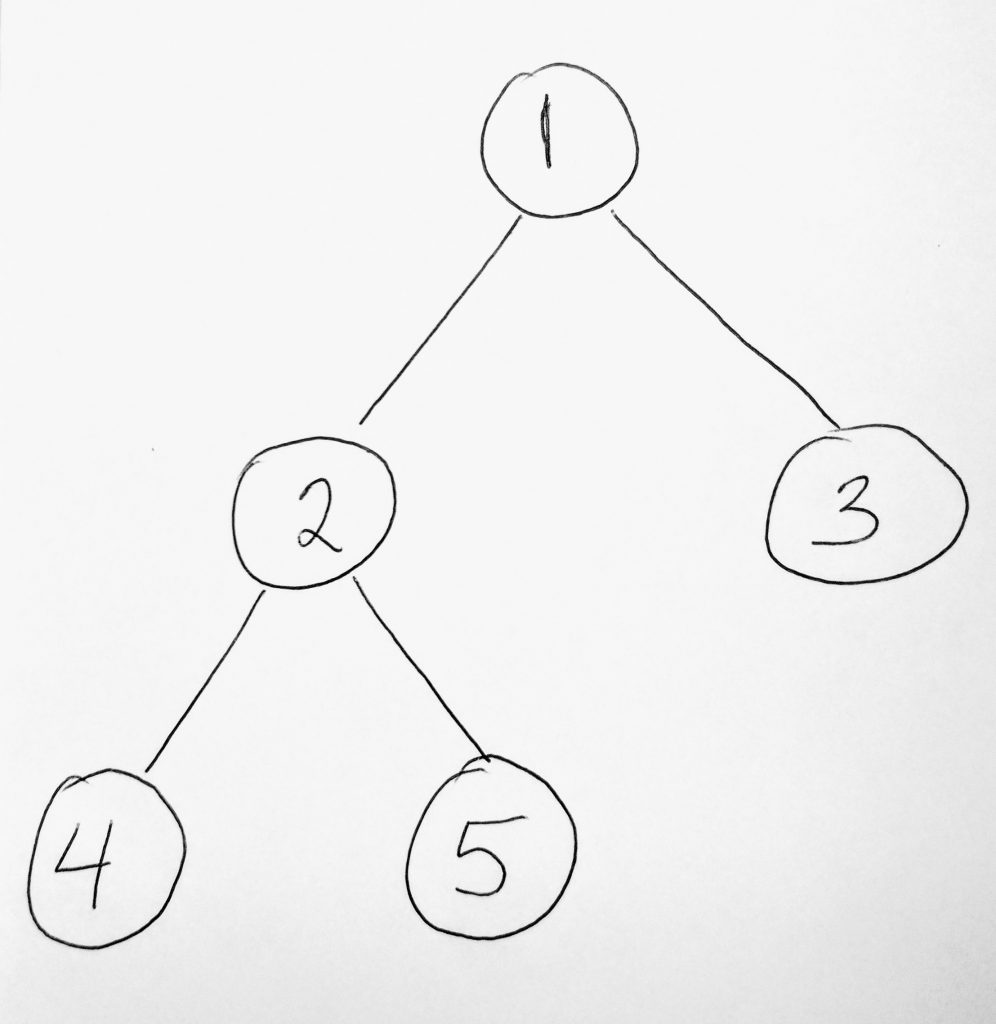
We will use the above diagram to illustrate the tree traversals we are talking about.
Inorder (Left Subtree [4, 2, 5], Root [1], Right Subtree [3]) -> 4 2 5 1 3
Preorder (Root[1], Left Subtree [4, 2, 5], Right Subtree [3]) – 1 2 4 5 3
Postorder (Left Subtree [4, 2, 5], Right Subtree [3], Root[1]) – 4 2 5 3 1
So our algorithms will recursively search in this order. For example, for the inorder function, we will first traverse the left subtree, then we will visit the root node, then finally we will traverse the subtree. In each traversal, all we want to do is print out the node values. We will use our toString method we wrote on our node. All we have to do is call this method in our function to output the value.
Lets first take a look at the inorder function.
See the Pen BST Traversal – inOrder by kofi (@scriptonian) on CodePen.
The code is nicely commented so you can see each step of the algorithm. You can see when the left & right subtree is being recursively iterated. But if you are like me, you might be wondering what all this magic is! You sort of understand what the recursive code might be doing but you don’t get it 100%. One thing is clear form the code however; when we called inOrder we pass it the root node of our BST. That sounds simple enough. We pass the root because the root has all the child nodes. We check to make sure the passed in root node is not null (otherwise we have nothing to work with). Somewhere in the code we print out the string value of the node using the toString method. I believe the secret to understanding what is going on with the recursive calls is to understand how call stacks work with function calls. This is something that happens naturally in javascript. When you execute a function, its put it onto the execution stack. So as we call functions recursively understanding this stacking order will take you far.
Let us step into what inOrder is doing with an example binary tree we used earlier ( 60, 30, 85, 95, 80, 35, 20 ). Please see the diagram below.
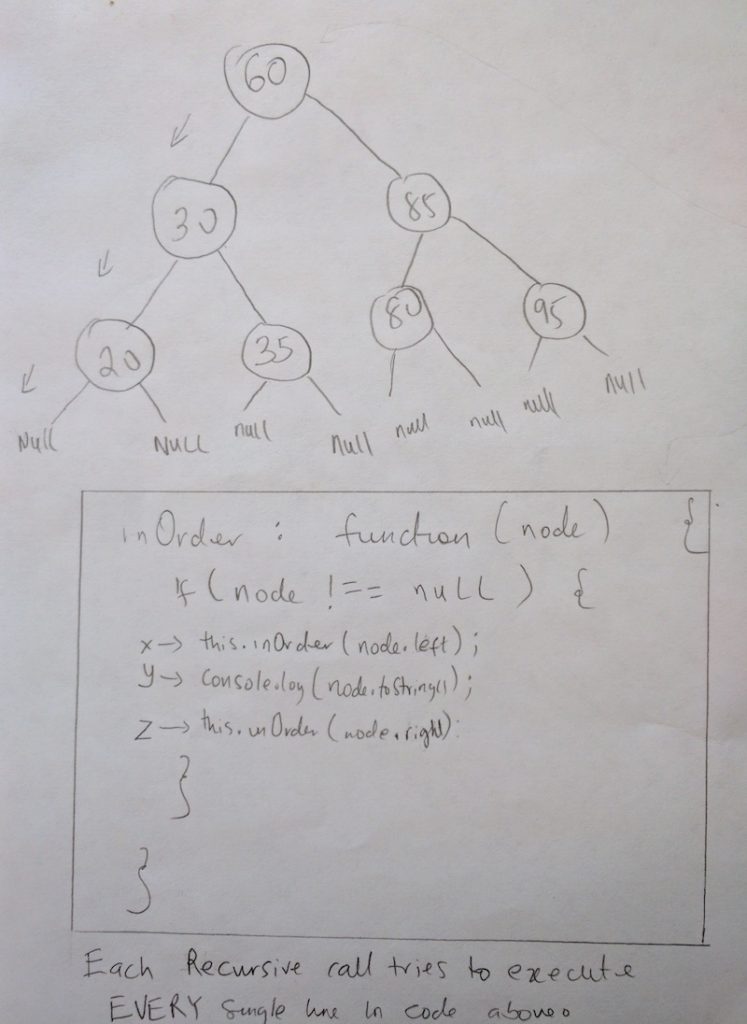
We saw this earlier in an example. The only difference here is that i have added NULL nodes to the leaf nodes (these are already there implicitly). I am adding them here for demonstration purposes only. I have also outlined our inOrder function and made a little note at the bottom. Take note of code lines X, Y, & Z (i will be referring to them regularly). During recursion, each time inOrder is called it attempts to execute each line in the function. Not only that, each function call during recursion is actually put on the execution stack. You can read more about this in my introduction post on javascript promises (first 3 paragraphs). So when we call inOrder with the 60 node ( the root node ), it’s put onto the execution stack. Take a look at this diagram
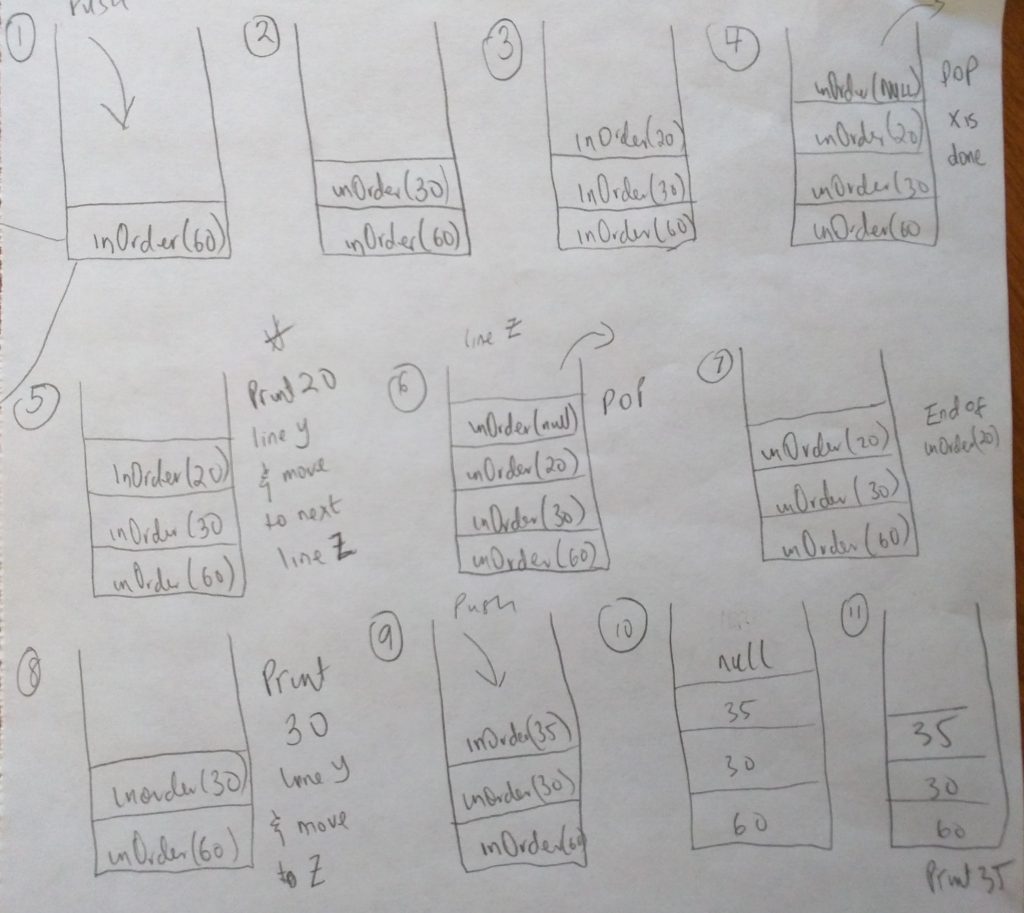 As you can see, in #1 in the above diagram, when we call inOrder with the root node, it gets added to the stack (like all functions do). Once its on the stack, it begins to execute code(line by line). In our code we first check to see if the node passed in is null (line before X). Since its not (remember its the 60 node we are starting with), we step into the if condition and try to run through X, Y and Z lines. As you can tell, line X calls inOrder again! It calls it passing the current nodes left property (which is 30). When this happens, we leave the current function execution and enter another. This function gets onto the execution stack (take a look at #2). The function tries to execute X, Y and Z again if the node is not null. But when it reaches X, inOrder is called again (with the 20 node). It gets added onto the stack. Please note that all this time, the other functions that have been added to the stack are now paused(60 and 30 they are waiting to resume)! They halt until its there turn to continue. When 20 node is added to the stack, it also tries to call inOrder again. However its called it with a node that is null (the reason i explicitly put the null in the diagram). This is #4 in the diagram. When that function tries to execute and gets to the first line where we check to see if the node is null, that statement becomes true so we exit that function call. When this happens the functions life is done and it is popped off the stack. When this happens we come back to the 20 node (#5 in diagram). BUT don’t forget, the last time we left the 20 node, we executed line X already. So now that we are done with that line, guess what line we move to? Yep, line Y. This line executes a console log and prints out 20. This is the first print that happens in our inOrder function. After this line is executed, we move to the last line in the function. We call inOrder passing in the right node of 20. This again gets added to the function stack (#6), but that execution is short lived as the right property of 20 is null. The function is popped off the stack and we return to 20 once again (#7). At this point, we have finished executing the last line for inOrder 20. So what happens, the function is popped off the stack and we get to #8. Now we are back to inOrder 30. The last time we left this fine, it executed line X. But we are done with that line now, we move to line Y which is to console log the current node. And Voila, we log 30 to the console. We now have 20,30 printed out during our execution. Then we move to the final line Z. We call inOrder again passing in the right node of 30. Which is 35, and that gets added onto the execution stack #9. As of this point you should really be seeing how recursion works. Its mind blowing really! We step into another function call, calling inOrder with null. Since the function simply returns for null nodes, that call is popped off the stack. Then we move to line Y. This will print 35. inOrder is called again, with the right null property of 35 which is null. At this point we have reached the each of the 35 node and that is popped off the stack. This takes as back to the end of the code in inOrder 30 (the end of the line). So that function also gets popped off the stack. We only have 60 left on the stack. But even that we have executed line X. We move to line Y and print 60. So far we have printed 20, 30, 35 and 60. The next thing to do is move to the last line (Z). Which is to call inOder passing in the right property of the tree, which is 85. This keeps on going on and on. When recursion is complete, you should have printed 20, 30, 35, 60, 80, 85 and 95. Whew! That was really tough to explain, but i really hope you get it! 🙂 I will not be going in-depth like this again, because you should now understand this on your own. Let us complete our traversal function.
As you can see, in #1 in the above diagram, when we call inOrder with the root node, it gets added to the stack (like all functions do). Once its on the stack, it begins to execute code(line by line). In our code we first check to see if the node passed in is null (line before X). Since its not (remember its the 60 node we are starting with), we step into the if condition and try to run through X, Y and Z lines. As you can tell, line X calls inOrder again! It calls it passing the current nodes left property (which is 30). When this happens, we leave the current function execution and enter another. This function gets onto the execution stack (take a look at #2). The function tries to execute X, Y and Z again if the node is not null. But when it reaches X, inOrder is called again (with the 20 node). It gets added onto the stack. Please note that all this time, the other functions that have been added to the stack are now paused(60 and 30 they are waiting to resume)! They halt until its there turn to continue. When 20 node is added to the stack, it also tries to call inOrder again. However its called it with a node that is null (the reason i explicitly put the null in the diagram). This is #4 in the diagram. When that function tries to execute and gets to the first line where we check to see if the node is null, that statement becomes true so we exit that function call. When this happens the functions life is done and it is popped off the stack. When this happens we come back to the 20 node (#5 in diagram). BUT don’t forget, the last time we left the 20 node, we executed line X already. So now that we are done with that line, guess what line we move to? Yep, line Y. This line executes a console log and prints out 20. This is the first print that happens in our inOrder function. After this line is executed, we move to the last line in the function. We call inOrder passing in the right node of 20. This again gets added to the function stack (#6), but that execution is short lived as the right property of 20 is null. The function is popped off the stack and we return to 20 once again (#7). At this point, we have finished executing the last line for inOrder 20. So what happens, the function is popped off the stack and we get to #8. Now we are back to inOrder 30. The last time we left this fine, it executed line X. But we are done with that line now, we move to line Y which is to console log the current node. And Voila, we log 30 to the console. We now have 20,30 printed out during our execution. Then we move to the final line Z. We call inOrder again passing in the right node of 30. Which is 35, and that gets added onto the execution stack #9. As of this point you should really be seeing how recursion works. Its mind blowing really! We step into another function call, calling inOrder with null. Since the function simply returns for null nodes, that call is popped off the stack. Then we move to line Y. This will print 35. inOrder is called again, with the right null property of 35 which is null. At this point we have reached the each of the 35 node and that is popped off the stack. This takes as back to the end of the code in inOrder 30 (the end of the line). So that function also gets popped off the stack. We only have 60 left on the stack. But even that we have executed line X. We move to line Y and print 60. So far we have printed 20, 30, 35 and 60. The next thing to do is move to the last line (Z). Which is to call inOder passing in the right property of the tree, which is 85. This keeps on going on and on. When recursion is complete, you should have printed 20, 30, 35, 60, 80, 85 and 95. Whew! That was really tough to explain, but i really hope you get it! 🙂 I will not be going in-depth like this again, because you should now understand this on your own. Let us complete our traversal function.
See the Pen Binary Search Tree Traversal by kofi (@scriptonian) on CodePen.
I could almost cry at how beautiful that code looks. So simple, yet so complex! I really pulled my hair understanding how this works so i could explain it to you. So kudos to you in you understand it (it means i did a good job explaining it). With time it only looks easier. So if you don’t fully grasp it, keep reading and re-reading, watch youtube videos. I particularly liked this one ( though its in java ). Lets complete our binary tree by implementing our find and remove methods.
Find / Search
A BST is a very efficient structure for finding data. Because it is self organizing the structure is able to discard large amounts of it data because it already knows how to priority search. On its farthest left, you find the smallest value. And on the farthest right, you find the maximum. This means that to find the max and min, you would only have to keep traveling in either direction, searching till you find the furthest right or left. To find specific values however we would have to start from the root node, and apply a few rules. First we check to make sure that the current node is not null, if so we return from the function with a null. If the current value we are looking for is equal to the current nodes value, then we return that node. Otherwise if the value we are looking for is less than the current node, then we recursively call our function to return the value. Otherwise the value is greater and we recursively search the right side of our tree. Lets take a look at the code.
See the Pen Binary Search Tree – Searching by kofi (@scriptonian) on CodePen.
This should all be self explanatory. Do ask questions if there are any. Lets move to our last method!
Removing
Now for the last method. We saved the hardest method for the final showdown! Remove is the most complex method when working with BST’s. So brace yourself. Here is how we are going to delete a node. First we find out if the node exists. If it doesn’t exist, we just exit the function. Simple enough. We can easily use our find method to do this (so we have done part of the work already). If the node to be removed exists, then perhaps it might be a leaf node. In that case we remove its parents pointer to the deleted node. In other words we return null to its parent (which gets garbage collected). This means that we have to keep track of the node we are deleting’s parent (which we have not done so far). Finally, if it is not a leaf node, then its possible it has one child node or 2 node children. If its got one child, we need to send the current nodes child to its parent. But even having one child depends on where the child is located(is it to the right or left?). This may be a little hard to visualize so lets draw a diagram.
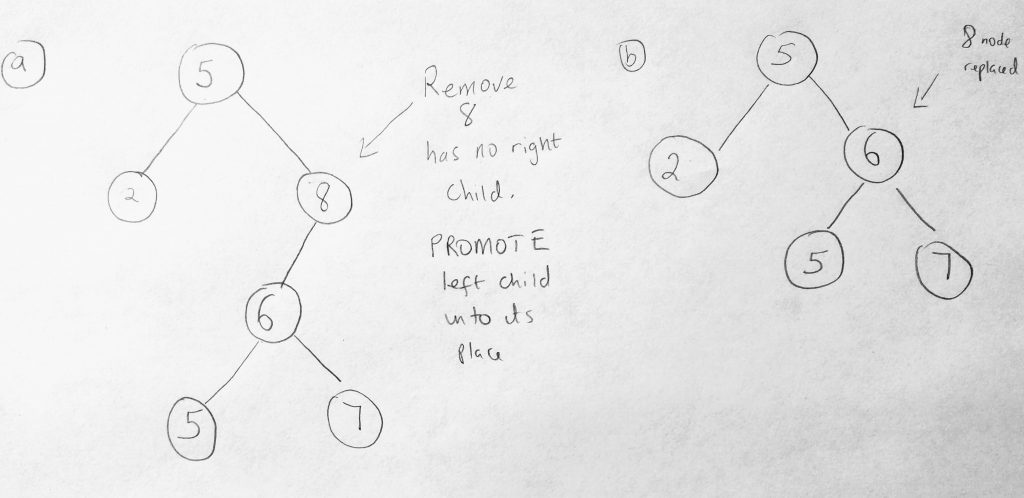
Here are the test cases we will be looking at. Lets just say the node we want to remove does not have a right child. In the diagram above, the 8 node doesn’t have a right child(so does 2, 5 and 7 – so this applies to them as well). The 8 node has a left child, and that is the node we want to remove. What we do in this case is promote the left child into the 8 nodes place when we delete. See diagram for before and after (b). Lets look at what happens if the if the node has a right child that does not a left child.
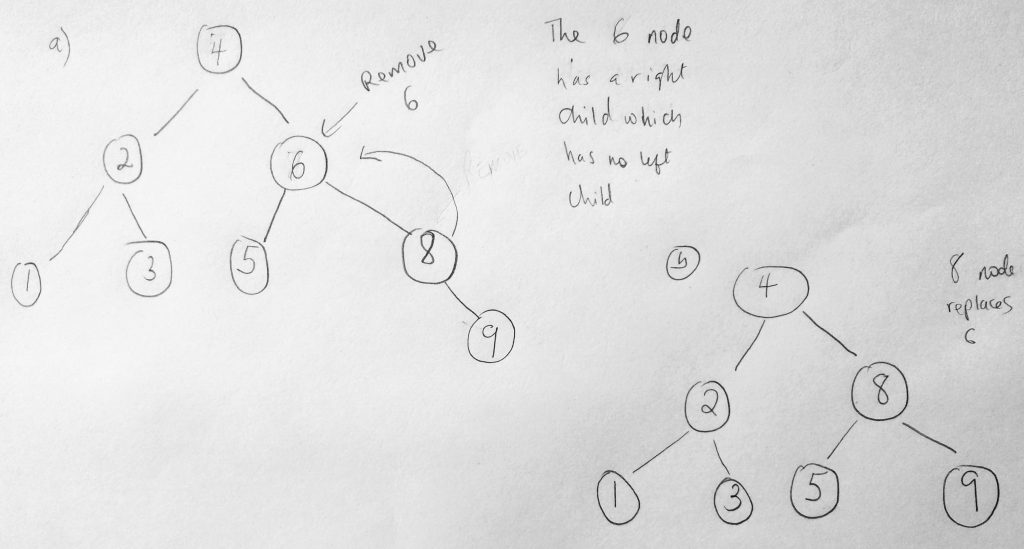
If the node to be removed, for example the 6 node has a right child that has no left child. Then the right of the 6 node is shifted up (like you see in the diagram). Finally what if the node we are removing has a right child which has a left child. In that case, the right child’s left most child node will replace the removed node.
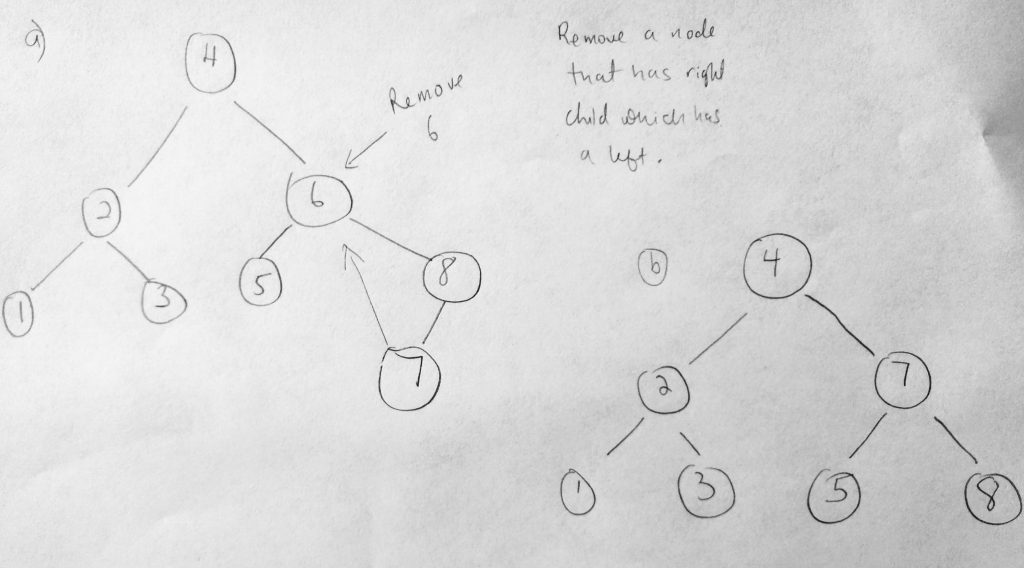
This case is quite unique. The node we wanted to remove is the 6 node. But that node has a right child who has a left child (the 7 node). In that case the 7 node is promote to the deleted node spot. As you can see, its involving to write such logic (there is a lot going on). But lets give it a try anyway. Ultimately it all begins by finding the node we want to delete. Lets take a look at the code.
See the Pen Javascript Binary Search Tree – Remove by kofi (@scriptonian) on CodePen.
As you can see, removing a node from a BST is no joke at all and i wouldn’t want to get asked in an interview question. The solution does not use recursion, however i have provided one in the github repo called delete (use whichever one suits you, though i think the recursion solution is a bit more elegant – few lines of code). The algorithm is also slightly different, but the results are still the same.
We are learned quite a lot about binary search trees. If you are interested to learn further i would advise to study Adelson-Velskii and Landi’s Trees (AVL) and Red-Black trees. The reasons for having these is because these trees are self balancing. When working with trees there are chances your tree grows in a skewing manner. Meaning one side of the tree will be longer (we spoke about this earlier). This can lead to performance issues and thus these two balancing algorithms are there to solve this problem. We will not be look at them in this post. But i might consider extending this post in the future to include them. We have learned to add and remove, search, traverse when working with binary search trees using our language of choice – Javascript. Lets wrap up this series by talking learning one more data structure: Graphs. Until then, see ya! Feel free to reach out on twitter as well ( @scriptonian ) if you have any questions.
Snippets now cool requires horizontal scrolling though.
Hi Amin, horizontal scrolling works both on android and ios. i tested myself. what device are you using?
really mind blowing!
thanks for reading 🙂 was a pleasure writing this… and glad you like it 🙂