
In the last post we talked about Maps. We learned that Maps can be referred to as dictionaries, associative arrays, etc. Sometimes you will also hear Maps or Sets being referred to as a Hash ( You will hear the likes of HashMaps or HashSets ). These types of key/value pair collections, are “Hash-bashed Data Structures”. What is hashing? In my very first post on data structures, i mentioned that Linked Lists are faster at adding data quicker to a collection, than it is at retrieving. Hashing is a way of storing data that makes retrieval and access extremely fast (Runtime complexity of O(1) for both retrieval, access, and deletion operations). Our collection is stored in a data structure known as a hash-table. This table is what makes data retrieval and storage so fast. When we looked at Maps in the last post (or even linked lists), anytime we wanted to find data, we had to traverse the whole collection in order to find it. Given a key, we would enumerate the whole thing for its value.Therefore it would take a long time we had a huge collection. Hash tables can be used to solve this problem. When using hash tables we can find data in the shortest amount of time because we already know which position in the table the value is stored. Like an array, we can retrieve the value at position 4 instantly. But as we said in the previous post, writing a statement like state[4] does not convey meaning (number index based structure, what if we don’t know its location?). When we tried to solve this problem with maps, we looked at how to write data structures so we could retrieve them using syntax that looked more like this state[‘NY’]. The only disadvantage here is we still would have to enumerate the entire object to get its value (though the syntax was nicer). Hashing employs a technique using something called a hash function. Given a key, it is passed to a function, and a value is returned right away (the key is hashed into a value). That value is used as an array index(in the hash table to retrieve values). The value of the index can be retrieved instantly because of its array nature.
Hash tables are poor when it comes to searching, or performing operations like max and min values (the binary tree is better at that, more on that in the next post). The whole point of having a hash is so we don’t search because we know what are we looking. So if you want to do search operations, use a different data structure. However if you want to find a value in the shortest amount of time, then hashing is the way to go. Lets try to visualize this flow.
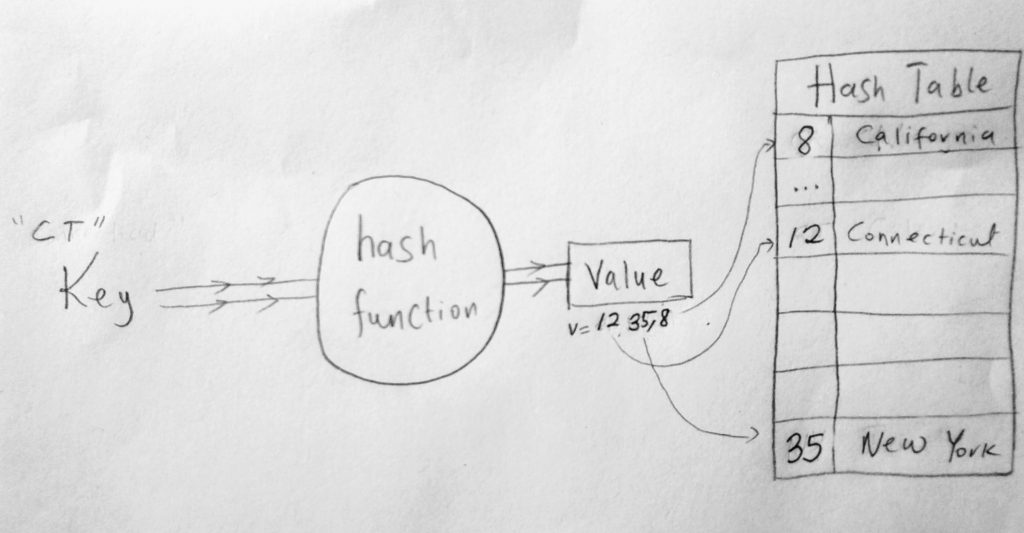
In the above diagram, we pass a key (“CT”) to a hash function. The function performs some magic and outputs a hash value (12). An array would have already been initialized with a fixed size. We map that hash value to that 12 index. Lets just say we want to put a key/value pair of {key: “CT”, value: “Connecticut”} in our hash table. Since CT is the key, we run it through a hash function. The function outputs a value of 12 (which now represents CT) and becomes our array index. We insert that value of CT, which is Connecticut at that index. The diagram does not show this, but we are also passing 2 other keys. Keys that hash out values of 35 for New York and 8 for California. The next time we want to find CT, we don’t need to search for it by iteration. All we do is ask for it, by first getting the value from the hash function, and returned the value from the table.
When working with hash tables, setting the size of the table (array) is important. As you can see the hash function outputs an index value, so setting a size is very important. If the function outputs a index value of 299 and the array(table) is not initialized to hold that many elements then you are likely to get an error. Your hash function (even built efficiently) can hash the same values for different keys. For example “CT” and “PA” can all hash a value of 12. When this happens we call it a collision. When this happens your table value at that index will be overridden (by the newest key). This is not a good thing! This means that we have to come up techniques for handling collisions: techniques such as separate chaining, linear probing and double hashing are used to handle these situation. We will take a look at some of these later on in this post. Lets dive deeper by building a basic Hashtable class! (This is also a HashMap).
HashTable implementation
Before we write our class, lets look at some of the common methods when working with Hash tables.
get: Returns a value based on a key. We could can called this find.
put: Adds a new item to our hash table given a key and value
remove: Removes a value from the hash table
displayTable: displays all key/values we have in our hash table.
HashTable Class
Lets write our hash table class. We will write one for ES5, and modern way of writing it. First using ES5
See the Pen HashTable Class – ES5 by kofi (@scriptonian) on CodePen.
Then using ES2015 and Beyond
See the Pen HashTable Class – Modern Javascript by kofi (@scriptonian) on CodePen.
This should look pretty standard. The only thing new here is we have an internal private function called _hashFunction. This method will be used internally to generated hash values. These values represent the index in the hash table ( so its important we keep it private to prevent others from hacking it, if that is a concerned ). Lets dive a little deeper into has hashing functions.
Remember that a purpose of the hash function is to take and input which is a key, and output a value, which represents an array index. It transforms a key into an index. Its important that index 8 for example is unique, as generating another index 8 will cause an override. This can be difficult to achieve. For example, given a key of MN for Minnesota, our hash function returns an array index of 5, because M = 1 and N = 4 and our algorithm adds 4+1 to get 5 as in index. What happens when we want an index for New Mexico, NM? We get 5 as well. If this happens Minnesota gets deleted. Not good. The truth is, its quite difficult to achieve this in practice. So writing a good hashing algorithm is no easy feat. So lets us set some requirements for our hash function. We would want our hashing function to be able to evenly distribute indexes uniformly in our table. If an index has already been generated because a value exists in that location, we need a way to compute another index. Our hash table should return values that are within the range of our table and should be able to calculate that quickly. A good hashing algorithm has to be performant. If you are doing a lot of crazy things just to generate a hash that takes a long time to execute, then that defeats the purpose. So pick your battles carefully.
Normally when building hashing functions you will have to work with the modulo operator ( % ). This can help us generate index values that are within the limit of our hash table size. If we had a hash table that was initialized to take 137 items, then we better not be generating values like 138 or we run into errors. This helps in uniformly distributing values across our table. Another thing that is good to do, is initialize the hash table with a prime number (notice the earlier example used an array size of 137 a prime number). Simple reason here is due to the use of modular arithmetic that is used in computing key values. So if our hashing algorithm produced a value of 568, we do 568 % 137 which is 20. Meaning that key would be located at index 20.
A simple hashing algorithm you might find is one that sums up the ASCII values of a given string. ASCII values are decimal values that represent characters. For example the letter ‘a’ has a value of 97. Look at the table here. As you can see we are not only dealing with decimal conversion, you have binary, octet, etc conversions as well. So what our algorithm will do is given a key string, it will add up all the ASCII values of the letters and divide that by the modulo. This will return the index value for our hash table. Lets write this simple function.
See the Pen Hash Functions in Javascript by kofi (@scriptonian) on CodePen.
In the above code sample, i have hash function written in 2 slightly different ways. You only need to be concerned about one for now (the first one, which is the simplest). All the function is doing is taking a string as a key, then it loops through the string and gets the ASCII value for each letter in the string, after which it sums it. We then return the indexed hash by doing a modulo operation. If you decide to test this function out for a hash table size of say 137 which a key of “kofi”, you get an index value returned of 14. If you tried “julie” you would get 126. This can be a powerful way of store data based on keys, however our hashing function is not strong enough. If i reverse key works, you will get the same values. Remember the example we used earlier about Minnesota and New Mexico. MN returns a value of 82, but NM which is New Mexico also returns 82! No good. Data will get overridden. Now in the sample code above i have provided a better hashing function (the second hash function). Give it a spin a see (with a data table size of 137). MN returns 64 but NM returns 94! This is because we can use some fancy math operations to return a 32 bit number instead. You might find this and that post interesting. So the second hash function is much much better than the first one because chances of getting duplicates are smaller. This does not mean getting duplicates is not possible. According to this article, you end up with a 1% chance of a collision after about 9300 tries, and a 50% chance after only 77000 tries. So as you can see its not the best of the best, but chances are you don’t need that many entries in your app anyway. I will talk about other ways of strengthening your hash functions later on in this post. Lets get back to our HashTable class.
put, get, remove & displayTable
We have the most important piece completed in our hash table (the hash function). We can now use it to finish building our HashTable class. Lets fill in the blanks.
Here is the ES5 full implementation
See the Pen HashTable Class Complete – ES5 by kofi (@scriptonian) on CodePen.
And here is the modern version ES2015 and beyond
See the Pen HashTable Class Complete – Modern Javascript by kofi (@scriptonian) on CodePen.
Lets step briefly through the code. The HashTable methods have very simple implementations. The put method takes a key and value, uses our internal hashFunction method to process the key parameter, returning a hash table index for that key. With that index we can store the value passed in to that location. The get function takes in a key and gets an index. With that index we can return a value in the table. remove also uses the same mechanisms as put and get. displayTable displays all the values in the table. Our HashTable is almost done, lets talk about how to handle collisions if they occur.
Handling Collions in Hash Tables
Collisions are bound to happen, and when they do we need to be prepared for them. Chances are that our hash function will hash values that are the same (might not happen regularly, because it will happen at some point). The easiest way of handling collisions in a hash table is to employ an algorithm called separate chaining. It is a technique which consists of creating another data structure, such as an array or linked list, for each element in the hash table. Here we can store colliding data. Here is a good way to visualize it. In our example earlier, we created a hash table with a size of 137. Imagine that each slot in the array where we store elements was yet another array or linked list. Take a look at this code sample
See the Pen Visualization of Separate Chaining by kofi (@scriptonian) on CodePen.
In order to employ separate chaining we will have to update our put, get and remove methods to accommodate for working with Linked Lists. We will also be adding another class called HashNode which now represents an element in the hash table (like an array of objects, where the object is of type HashNode). Lets take a look at this class in both ES5 and ES2015 and above.
In ES5
See the Pen HashNode – ES5 by kofi (@scriptonian) on CodePen.
ES2015 and above
See the Pen HashNode – ES2015 and beyond by kofi (@scriptonian) on CodePen.
Not a lot is going on here. The HashNode class only stores the key and value in an Object. We also have a toString helper method to help us query the object if need be. We may want to know what key/value we are working with in our data structure (for eg. during an iteration).
Enhancing put(), get() and remove()
We now need to upgrade our helper methods. Since we are trying to solve the problem of collisions, by storing our key/value pairs in linked lists, we will use the doubly linked list implementation discussed in an earlier post. Because we have written this class already in another post i am not going to explain how linked lists work. I have created a hashing-examples in the github repo. I have created a file called linked-list.js and which is an import of the linked list work we did earlier. In the html file, you will find see the imported script tag. Lets take a look at our updates to these methods
See the Pen HashTable Separate Chaining (ES5) – Put, Get & Remove by kofi (@scriptonian) on CodePen.
Ok as you can see, there is quite a lot going on in here. Starting with out put method, we first retrieve the index for the key we are seeking (from the hash function). If that key is undefined, meaning there is nothing in that location, a brand new linked list is created. Next we create a new HashNode object. Remember our hash table will only consist of HashNode objects. We then use the addToTail method of the linked list to add this node to our linked list. Next our get method is used to retrieve a value based on a key passed it to. Like most methods a key is mapped to an index within our table. If that index is not undefined, meaning there is data in that location, we use the linked list’s find method which returns an array of linked list nodes. We loop through that array and display the values found in it to the user. Remove also does something similar. We use the linked list’s find method to get a list of nodes we want to remove and call the remove method of the linked list to get rid of it. Lets talk about another way to prevent collision: linear probing.
Linear probing, also known as open-addressing hashing, is another technique we can use to solve the problem is collision within our hash table. Previously we saw how do solve this with linked lists. In this case, we will see how to solve it using the same hash table array. When we add an item to the table and there is a collision, we try the next available spot. So we keep incrementing by 1 until we find a free location. Other implementations using open-addressing are using quadratic probing and double hashing. We will not be covering these in this post, but feel free to explore on your own (knowledge is power, and google is your friend).
This technique is especially useful if you are going to have a lot of elements to store. By a lot i mean if the number of elements will be more than half of the array initialized, the linear probing is better. If the number of elements will be less than half, the separate chaining will be better. Sometimes you will hear this being referred to as load factor. If the load factor is less that .5 (which is 50% of below, then use separate chaining, if load factor is greater than .5, then use linear probing). Please read more about this ok wikipedia. In order to use this technique we are going to update our put and get methods. Everything else stays the same. Lets take a look at the new methods. Please find this source in the github repo (hashtable-linear-probing.js).
See the Pen Linear probing GET and PUT – Hash Table by kofi (@scriptonian) on CodePen.
Lets go over what these methods are doing and wrap up this post. In our put method, we start off as we have always done. We get a key value and get the hash table value for that key. This is the index slot in our array. If that slot if undefined, it means there is nothing there and we insert the data. However if there is something in that slot, we start a while loop beginning from that last index. As long as the next slot is not undefined (meaning its not available) we keep looping till we find a spot. When we do we insert the new data there (else we return undefined, meaning we were not able to insert – end of function). Getting the value is a little but more involved, but not so complex. Because we know the likelihood of collision, anytime we search for a key, we have to assume that is not the slot its located at. After we get the interested hash table index, we run an iteration. As long as the current index is not undefined (meaning there is something there), we check to see if the key of the current slot item equals to the interested key we are looking for. If it is we simply return the objects value, else we continue our iteration until we find the interested key. Note that this is not necessarily a bad thing. If there is only one item in that location, it is returned right away, which is a constant runtime. However if not found, then it would be O(N).
Hash tables are very powerful. If you want to insert or retrieve data very quickly, then this is the data structure for us to use. However remember if you intend on doing searching, using a hash table might not be most ideal. Not all applications are created equal. Normally the requirements for the application will let you know which techniques to use for your hash table or which data structure is best suited. There isn’t a one for all data structure. I hope you have a better idea of what hashing is, as well as hash tables functions. I have definitely learned a lot myself writing this post. But there are 2 more data structures to learn, lets talk about Trees and Graphs in our next post. Feel free to reach out on twitter as well ( @scriptonian ) if you have any questions.
Hi I really enjoyed the post. I suggest you improve the way you display code snippets(github.com fine). It’s difficult to read the code on mobile. Chrome 58 for Android.
Hi Amin, are you talking about Codepen? I will investigate this issue. Thanks for letting me know. You can also try landscape mode to get more screen size space.